

Un 'web scraper' es una herramienta que permite a los usuarios extraer datos de diferentes sitios web. El raspador web toma la información recogida y exporta los datos a una hoja de cálculo para su posterior análisis. El raspador de datos web es totalmente legal en Estados Unidos y es una herramienta útil para cualquier empresa.
La gente suele pasar horas navegando por la web y recopilando manualmente la información que necesita, lo que no es la tarea más divertida, y conduce a errores debido al "factor humano": el cansancio o el aburrimiento. Al implementar la automatización del raspado web, las empresas pueden extraer datos de manera más eficiente y reasignar a los empleados a tareas comerciales más cruciales y orientadas al retorno de la inversión.
El raspado web con la automatización robótica de procesos (RPA) utiliza bots para automatizar el proceso de extracción de datos web de sitios seleccionados y su almacenamiento para su uso. La RPA ofrece resultados más rápidos, eliminando la necesidad de introducir datos manualmente y reduciendo los errores humanos.
Cómo se utiliza Web Scraper
Existen innumerables formas de utilizar los raspadores web en los procesos empresariales de casi todos los departamentos. Desde el raspado web para los equipos de ventas y marketing hasta los de contabilidad y finanzas, hemos elaborado una lista de los casos de uso más comunes para los raspadores web. Algunos ejemplos de raspadores web con RPA son:
- Extraiga los datos de los productos para comparar las compras en Amazon, eBay u otros sitios similares.
- La extracción de los precios de las acciones para tomar una decisión de inversión más informada por los datos.
- Extracción de información para el seguimiento de la marca y la empresa.
- Utilización de una herramienta de raspado RPA para los datos del sitio antes de la migración del mismo.
- Aproveche un raspado de RPA para obtener información financiera para un estudio de mercado en profundidad.
- Los bots programados pueden recopilar algunos datos de las redes sociales para comprender la visión y la mentalidad de los clientes de forma rápida y sencilla.
Una vez extraídos, los datos se almacenan en bases de datos o se transfieren a otro sistema o aplicación. La automatización no sólo permite adquirir datos con rapidez, sino que puede extraer información procesable y almacenarla automáticamente donde sea necesario, ya sea una base de datos u otro sistema.
Las oportunidades de implementar con éxito un raspador de sitios web en su trabajo diario son casi infinitas. Las herramientas de raspado web le ayudan a usted y a su equipo a profundizar en temas específicos para obtener información más detallada para la planificación estratégica y las tareas a corto plazo.
Proceso y soluciones de Web Scraping
El raspado de datos en la web a partir de diversas fuentes implica un algoritmo sencillo, adaptado a los objetivos y requisitos comerciales de cada empresa. Los pasos de raspado de la web implican:
- Localización de los datos necesarios para la extracción.
- Escribir y ejecutar código.
- Almacenar los datos en el formato requerido.
Hay muchos tipos de soluciones de raspado web: desde las operaciones manuales de copiar y pegar hasta las extensiones del navegador y la automatización de procesos robóticos. Sin embargo, el RPA sigue siendo la solución más popular y eficaz cuando se trata de raspar grandes cantidades de datos web.
Comparación de soluciones de raspado web
| Parámetro | Copia y pega manual | Extensión del navegador | RPA |
| Capacidad de raspado | Puede reducir cualquier cantidad humanamente posible | Las extensiones del navegador, como ChromeScraper, pueden raspar una página a la vez. | Las herramientas de RPA como el bot de raspado web de ElectroNeek pueden raspar cualquier cantidad de datos. |
| Coste | Es barato comparado con las otras dos opciones. | Barato, con algunas opciones de pago. Extensiones populares: ChromeScraper, Outwit hub Firefox | Implica más gastos que las otras dos opciones. Sin embargo, con el modelo de suscripción de ElectroNeek, el coste inicial se reduce drásticamente. |
| Tempo | Quanto maior a quantidade de dados a serem raspados, mais longo será o processo. | É mais rápido do que o processo manual, mas mais longo do que a automação, pois pode raspar apenas uma página de cada vez. | Mucho más rápido que las soluciones manuales y de extensión del navegador. Puede raspar una gran cantidad de datos en sólo unos minutos. |
| Eficiencia | Es más propenso a los errores humanos que las otras dos opciones | Una pequeña posibilidad de errores, ya que implica más intervención manual que las soluciones RPA. | Sin errores, ya que casi no hay intervención manual. |
| Flexibilidad | Es fácil de hacer, pero está limitado a la capacidad humana, ya que todo es manual. | Menos flexible que RPA en términos de personalización y manejo de elementos de la interfaz de usuario como el botón "Cargar más". | Fácil de instalar y muy personalizable en comparación con las otras dos opciones. También permite manejar fácilmente elementos complejos de la interfaz de usuario. |
Ventajas del uso de RPA para el Web Scraping
Aprovechar una herramienta de raspado de datos automatizado para sitios web ofrece las siguientes ventajas:
- Los datos recogidos por un bot RPA son más precisos en comparación con la entrada de datos manual.
- La automatización agiliza el proceso de raspado de la web. Tareas que tardan semanas en realizarse a mano se hacen en unas pocas horas.
- Las soluciones de automatización son fáciles de implantar e integrar en el ecosistema informático de una empresa.
- Se requiere poco mantenimiento, ya que los raspadores web automáticos casi no requieren mantenimiento a largo plazo.
Los bots RPA integrados con otras tecnologías y herramientas, como el aprendizaje automático, hacen del bot una herramienta aún más potente. Por ejemplo, el aprendizaje automático combinado con bots puede localizar los sitios web de las empresas a partir de sus logotipos.
Desafíos del uso de RPA para el Web Scraping
Un raspador de sitios web de RPA depende en gran medida de los elementos de la interfaz gráfica de usuario para localizar los datos relevantes, lo que dificulta la automatización cuando las páginas web no muestran el contenido de forma coherente. Algunas de las principales limitaciones del scraping web son:
- Características de la interfaz de usuario (UI): Algunas características de la UI, como el desplazamiento infinito, los mensajes emergentes y el contenido dinámico cambiante de la web, dificultan la extracción de datos por parte de los scrapers. La solución sería la programación de bots adicionales para funciones complejas específicas.
- Botón "Cargar más": Muchas páginas cargan los datos en pequeñas partes utilizando el botón "Cargar más". En estos casos, el bot se detendrá al final de una parte visible y perderá más información sin explorar más datos. A continuación, puede crear un bucle if dentro del programa de un bot para que haga clic en el botón "Cargar más" hasta que no haya más botones en un sitio.
- Anuncios emergentes: estos anuncios suelen ocultar elementos de la interfaz gráfica de usuario desde la perspectiva de los bots de APR y dificultan la extracción de datos. Una solución eficaz sería añadir la extensión ADBlocker a su navegador.
- Sistemas protegidos: Algunas páginas web utilizan tecnología de seguridad avanzada para evitar que su sitio se autodescargue, lo que se convierte en un obstáculo más. Hay dos soluciones posibles: en primer lugar, trabajar con una empresa que ofrezca datos web como servicio, o combinar RPA con servidores proxy para construir bots que no puedan distinguirse de los humanos.
Automatización del raspado web con RPA
El raspado web automatizado implica que los robots RPA realicen tareas repetitivas. El bot imita las acciones humanas en los procesos de la interfaz gráfica de usuario (GUI). El flujo de trabajo es similar al descrito en la sección anterior; la única diferencia es que un bot RPA realiza todas las acciones: desde la búsqueda de URLs hasta la extracción y el almacenamiento de datos relevantes.
A diferencia del flujo de trabajo de bricolaje, con RPA no hay que escribir código cada vez que se recogen nuevos datos de nuevas fuentes. Las plataformas de RPA suelen ofrecer herramientas integradas para el raspado de la web, lo que ahorra tiempo y es mucho más fácil de usar.
Supongamos que quiere automatizar el procedimiento de recopilación de noticias sobre diversos temas. El primer paso es crear un archivo simple (como un archivo Excel) para que el bot almacene los datos recogidos. En segundo lugar, el bot debe estar programado y hacer un bucle con las consultas de búsqueda y los resultados de la carga. Por último, el bot RPA puede analizar los datos relevantes, extraerlos y almacenarlos con rapidez y precisión.
Los bots de RPA web ejecutan todas las aplicaciones de raspado web en tiempo real con una tasa de error cercana a cero en comparación con los procesos manuales.
Cómo realizar el raspado con ElectroNeek
Utilicemos la herramienta de raspado web de ElectroNeek como ejemplo para ilustrar el funcionamiento del raspado web automático. Vamos a crear un bot que deseche los datos de la tienda online de Amazon. También puede descargar este bot de ejemplo de la Biblioteca de Bots de ElectroNeek: amazon-search-result.zip.
Por ejemplo, queremos abrir Amazon, encontrar libros históricos y extraer todos los enlaces y títulos de los resultados de la búsqueda. El proceso de raspado de la web seguirá los siguientes pasos.
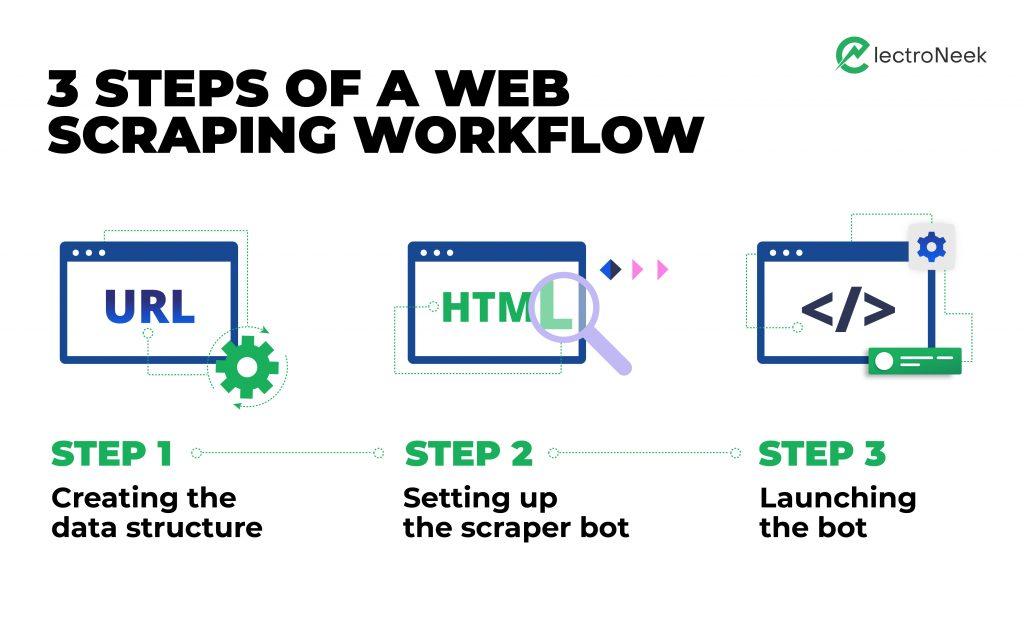
Paso 1: Crear la estructura de datos
Não precisamos emular a abertura da Amazon e a navegação para a categoria. Substituiremos todas eNo es necesario emular la apertura de Amazon y la navegación hasta la categoría. Sustituiremos todas estas acciones por un solo enlace que ya contiene los resultados de la búsqueda. Abra manualmente el navegador Google Chrome y copie y pegue el enlace: https://www.amazon.com/b/ref=gbpp_itr_m-3_01bf_History?node=9&ie=UTF8.
Abra ElectroNeek's Studio Pro y haga clic en Archivo → Crear diagrama de flujo de relaciones de elementos.
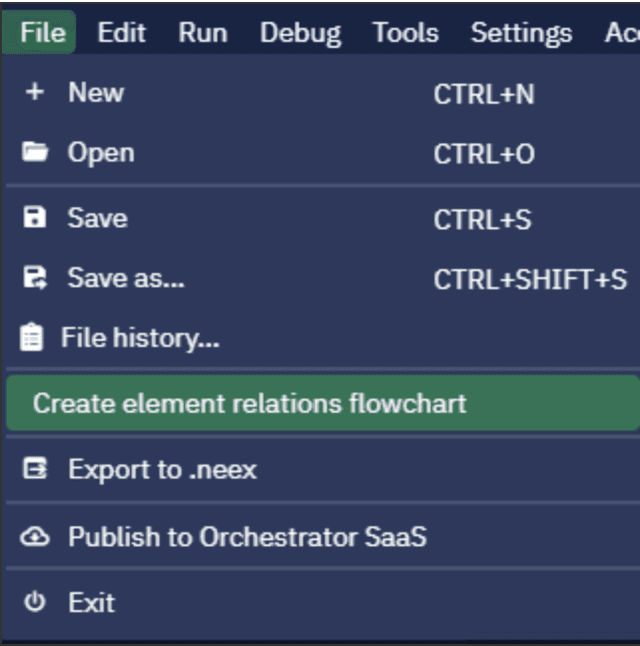
Se abre una pantalla independiente con un bloque de Start (Inicio) y una lista de funciones en el panel izquierdo (ahora sólo tiene una parte: elemento de datos). Guardemos el archivo y llamémoslo amazon_search_result.rel.
A continuación, construye la estructura de datos arrastrando y soltando la función Data Element (Elemento de datos( en el lienzo y conectándola con el bloque Start (Inicio).
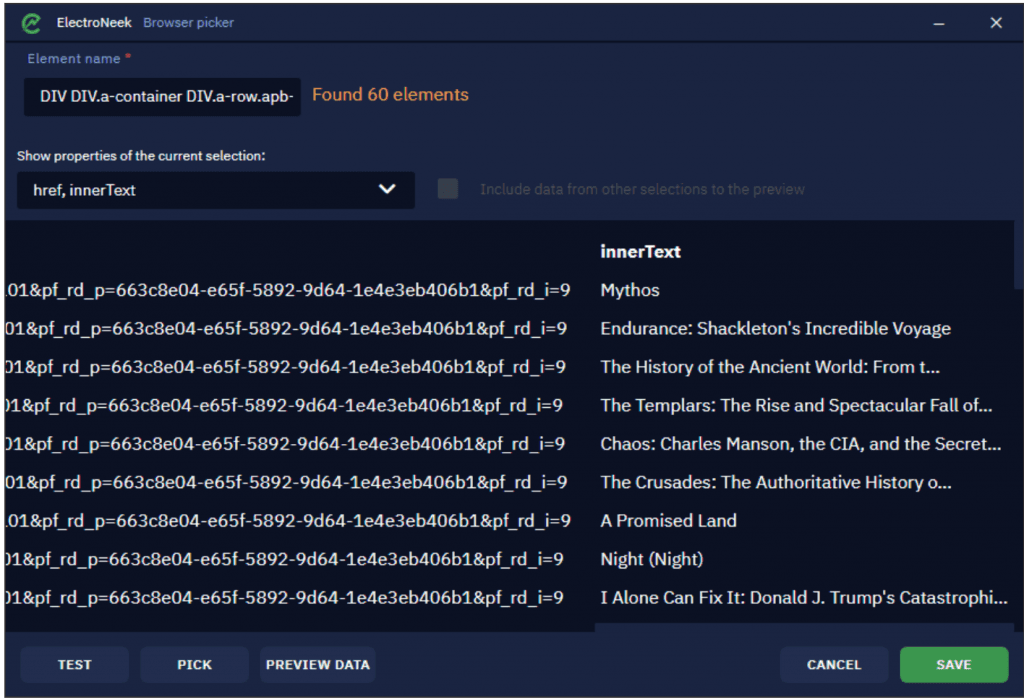
Una vez hecho esto, seleccione todos los elementos necesarios (títulos de libros, en nuestro caso) de los que queremos extraer datos. Haga clic en Pick (Elegir) nuevo elemento para iniciar el modo de selección. Haciendo clic en Preview Data (Vista previa de los datos), puede obtener una vista previa de los enlaces extraídos.
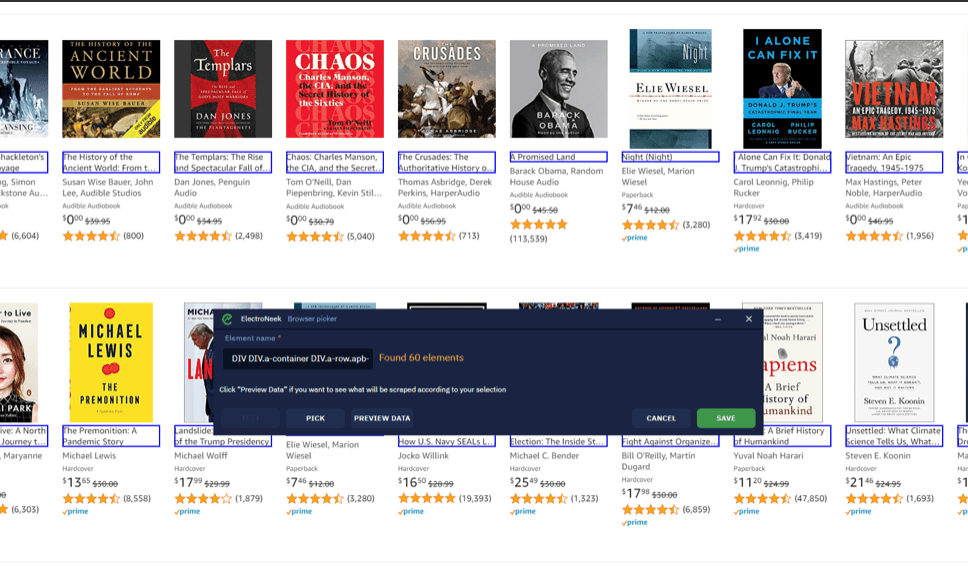
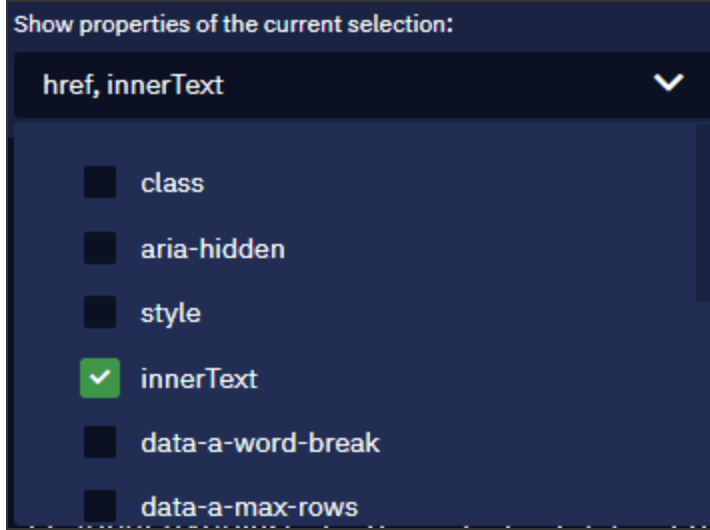
En la lista desplegable de enlaces extraídos, puede ver los atributos de los que leemos los datos. Como los títulos seleccionados son esencialmente enlaces, el atributo de salida por defecto es .
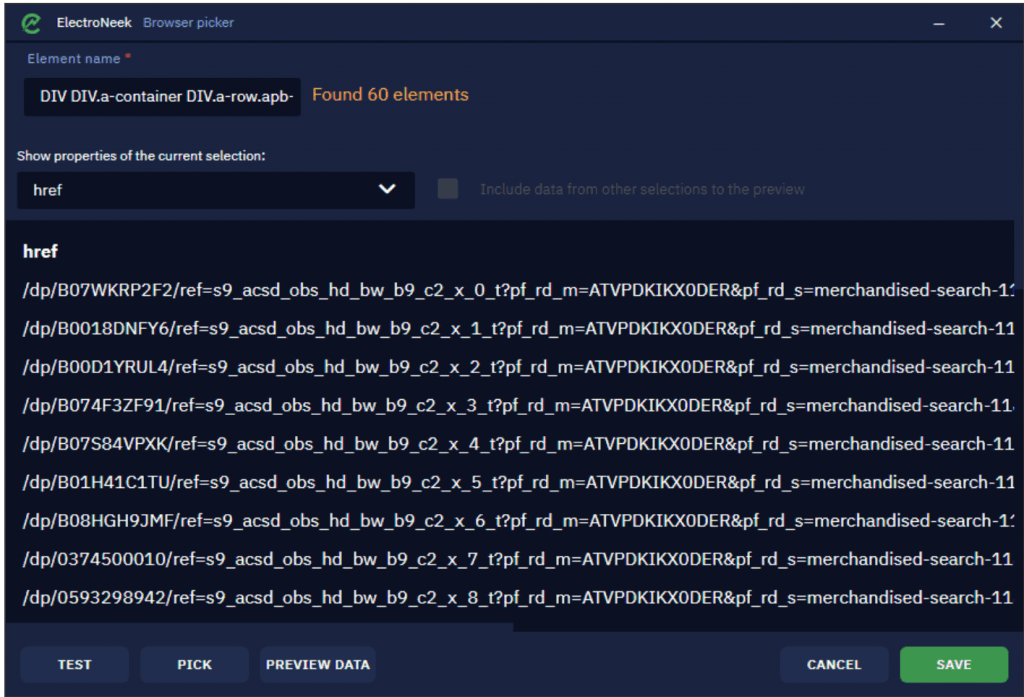
También puedes añadir más atributos para leer los datos. Haga clic en la lista desplegable y seleccione un nuevo atributo: . Este atributo se utiliza para extraer los títulos (el texto en sí).
Después de añadir el atributo, habrá otra columna para ver el rango de datos, por lo que es posible que tenga que desplazarse hacia la derecha. Debe tener en cuenta el rango de datos para comprender mejor cómo probar su selección.
Siga el proceso exacto para crear tantos elementos de datos como sea necesario.
Por último, antes de crear un archivo ".neek" (Un archivo ".neek" es un archivo en ElectroNeek Studio; sólo puede ser ejecutado en Studio por bot runner), necesita probar su estructura de datos. Haz clic en Inicio y pega en él el enlace que hemos publicado anteriormente. Se activará el botón de prueba de raspado.

Cuando hagamos clic en Test Scraping (Probar raspado), el bot abrirá una nueva pestaña y raspará los datos desde allí. El resultado se guarda en la variable de la pestaña Variables. Guarde todos los cambios en el archivo ".rel".
Paso 2: Configuración del bot
Arrastre y suelte la actividad Raspar datos estructurados de la sección Web Automation → Browser.
Haga clic en el botón Pick y seleccione el archivo ".rel" que guardamos en la sección anterior.
Em A continuación, haga clic en la actividad Guardar tabla después de Raspar dados estructurados . Ya está configurado para que el archivo Excel resultante se coloque en la misma carpeta donde se encuentra el bot. Pero puedes modificarlo si es necesario. Por ejemplo, puedes guardar el resultado en una tabla de Google Sheets. Lo dejamos como está.

Paso 3: Ejecutar el bot de raspado
El último paso es ejecutar el bot que raspará los datos y los guardará en una tabla. Navega hasta la carpeta con el bot, abre la tabla y comprueba el resultado.
Por qué elegir la herramienta de raspado ElectroNeek
Con la herramienta de raspado web de ElectroNeek, no necesita ser un ingeniero para recoger y procesar automáticamente los datos que necesita de la web. No es necesario escribir complejas secuencias de comandos: todo lo que tiene que hacer es mostrar al sistema exactamente los datos que desea, eligiendo varios elementos deseados (como los títulos de libros históricos en nuestro ejemplo anterior), y la herramienta hará el resto. Por lo general, la herramienta extrae los datos de un sitio web individual en menos de un segundo.
Si está interesado en saber más sobre nosotros y nuestros bots de raspado web, póngase en contacto con nuestro equipo de asistencia para concertar una demonstración y descobrir como puede aprovechar la automatización del raspado web en su negocio.