

Um 'web scraper'(ou raspador da web) é uma ferramenta que permite aos usuários extrair dados de diferentes websites. O raspador da web leva as informações coletadas e exporta os dados para uma planilha para uma análise mais profunda. O raspador de dados da web é inteiramente legal nos EUA e é uma ferramenta útil para qualquer negócio.
As pessoas muitas vezes passam horas navegando na rede e coletando manualmente as informações de que precisam, o que não é a tarefa mais divertida, levando a erros por causa do "fator humano": cansaço ou tédio. Ao implementar a automação da raspagem da web, as empresas podem extrair dados de forma mais eficiente e redistribuir os funcionários para tarefas comerciais mais orientadas para o ROI e cruciais.
A raspagem da web com Automação Robótica de Processos (RPA) utiliza bots para automatizar o processo de extração de dados web de sites selecionados e armazená-los para uso. O RPA proporciona resultados mais rápidos, eliminando a necessidade de entrada manual de dados e reduzindo os erros humanos.
Como a raspagem da web é utilizada
Há inúmeras maneiras de usar raspadores de web nos processos comerciais em quase todos os departamentos. Desde a raspagem da web para equipes de vendas e marketing até equipes de contabilidade e finanças, elaboramos uma lista dos casos mais comuns de uso de raspadores de web. Os exemplos de raspadores de web com RPA incluem:
- Extrair dados de produtos para comparação de compras na Amazon, eBay, ou outros sites similares.
- Puxar os preços das ações para uma decisão de investimento mais informada sobre os dados.
- Extração de informações para monitoramento da marca e da empresa.
- Utilizar uma ferramenta de raspagem RPA para dados do site antes da migração de um site.
- Alavancar uma raspagem RPA para buscar informações financeiras para uma pesquisa de mercado aprofundada.
- Os bots programados podem reunir alguns dados da mídia social para entender a visão e a mentalidade dos clientes de forma fácil e rápida.
Uma vez puxados, os dados são armazenados em bancos de dados ou transferidos para outro sistema ou aplicação. A automação não só permite adquirir dados rapidamente, mas pode puxar informações acionáveis e armazená-las automaticamente onde necessário, seja um banco de dados ou outro sistema.
As oportunidades para implementar com sucesso um raspador de websites em seu trabalho diário são quase infinitas. As ferramentas de raspagem da Web ajudam você e sua equipe a se aprofundar em tópicos específicos para obter informações mais detalhadas para planejamento estratégico e tarefas de curto prazo.
Processo e soluções de raspagem da web
Os dados de raspagem da Web de várias fontes envolvem um algoritmo simples, adaptado aos objetivos e requisitos comerciais de cada empresa. As etapas de raspagem da web envolvem:
- Identificação de URLs relevantes.
- Localização de dados necessários para extração.
- Escrever e executar o código.
- Armazenar dados no formato requerido.
Existem muitos tipos de soluções de raspagem da Web: desde operações manuais de copiar colar até extensões de browser e automação robótica de processos. Entretanto, o RPA continua sendo a solução mais popular e eficaz quando se trata de raspar grandes quantidades de dados da web.
Comparação de soluções de raspagem da Web
| Parâmetro | Copia e Cola Manual | Extensão de Browser | RPA |
| Capadidade de Raspagem | Pode raspar qualquer quantidade humanamente possível | Extensões de Browser como ChromeScraper podem raspar uma página por vez. | Ferramentas de RPA como o bot de raspagem da Web da ElectroNeek podem raspar qualquer quantidade de dados. |
| Custo | Barato em comparação com as outras duas opções. | Barato, com algumas opções pagas. Extensões populares: ChromeScraper, Outwit hub Firefox | Envolve mais despesas do que as outras duas opções. Entretanto, com o modelo de assinatura da ElectroNeek, o custo inicial é reduzido drasticamente. |
| Tempo | Quanto maior a quantidade de dados a serem raspados, mais longo será o processo. | É mais rápido do que o processo manual, mas mais longo do que a automação, pois pode raspar apenas uma página de cada vez. | Muito mais rápido que as soluções de extensão manual e de navegador. Ele pode raspar uma grande quantidade de dados em apenas alguns minutos. |
| Eficiência | Propenso a mais erros humanos do que as outras duas opções | Uma pequena chance de erros, pois envolve mais intervenção manual do que as soluções de RPA. | Livre de erros, pois não envolve quase nenhuma intervenção manual. |
| Flexibilidade | Fácil de fazer, mas é limitado à capacidade humana, pois tudo é manual. | Menos flexível que o RPA em termos de personalização e de lidar com elementos de IU como o botão "Load more" (Carregar mais). | Fácil de instalar e altamente personalizável em comparação com as outras duas opções. Permite também lidar facilmente com elementos complexos de IU. |
Benefícios de usar o RPA para Raspagem da Web
Alavancar uma ferramenta de raspagem automatizada de dados para sites da Web oferece os seguintes benefícios:
- Os dados coletados por um bot de RPA são mais precisos em comparação com a entrada manual de dados.
- A automação torna o processo de raspagem da web mais rápido. Tarefas que levam semanas para serem concluídas com as mãos são feitas em poucas horas.
- As soluções de automação são fáceis de implementar e de integrar dentro do ecossistema de TI de uma empresa.
- É necessária pouca manutenção, pois os raspadores automáticos da web não requerem quase nenhuma manutenção a longo prazo.
Os bots de RPA integrados com outras tecnologias e ferramentas, como a aprendizagem de máquinas, tornam o bot uma ferramenta ainda mais poderosa. Por exemplo, o aprendizado de máquinas combinado com os bots pode localizar os sites das empresas a partir de seus logotipos.
Desafios de se usar RPA para Raspagem da Web
Um raspador de sites RPA depende muito de elementos GUI para localizar dados relevantes, tornando desafiador automatizar quando as páginas da web não exibem conteúdo de forma consistente. Algumas das principais limitações de raspagem da web incluem:
- Recursos de Interface do Usuário (IU): Algumas características da IU, tais como rolagem infinita, mensagens popup e alteração do conteúdo dinâmico da web tornam difícil para os raspadores lidar com a extração de dados. A solução seria programação adicional de bot para características complexas específicas.
- Botão "Carregar Mais": Muitas páginas carregam dados em pequenas partes usando o botão "Load more". Nesses casos, o bot vai parar no final de uma parte visível e perder mais informações sem explorar mais dados. Pode, então, criar um if-loop dentro do programa de um bot para clicar no botão "Load more" (carregar mais) até não haver mais botões em um site.
- Anúncios pop-up: Estes anúncios muitas vezes escondem elementos da GUI do ponto de vista dos bots de RPA e prejudicam a extração de dados. Uma solução eficaz seria adicionar a extensão ADBlocker para seu navegador.
- Sistemas Protegidos: Algumas páginas da web utilizam tecnologia avançada de segurança para evitar que seu site se raspe automaticamente, o que se torna mais um bloqueio de estrada. Existem duas soluções possíveis: primeiro, trabalhar com uma empresa que oferece dados web como serviço, ou combinar RPA com servidores proxy para construir bots que não podem ser distinguidos de humanos.
Automatizando Raspagem Web com o RPA
A raspagem automatizada da web envolve os bots de RPA realizando tarefas repetitivas. O bot imita as ações humanas nos processos de interface gráfica do usuário (GUI). O fluxo de trabalho é semelhante ao descrito na seção anterior; a única diferença é que um bot RPA executa todas as ações: desde encontrar URLs até extrair e salvar dados relevantes.
Ao contrário do fluxo de trabalho DIY, com o RPA, você não precisa escrever código toda vez que coleta novos dados de novas fontes. As plataformas RPA geralmente fornecem ferramentas integradas para a raspagem da web, o que economiza tempo e é muito mais fácil de usar.
Digamos que você queira automatizar o procedimento de coleta de notícias sobre vários tópicos. O primeiro passo é criar um arquivo simples (como um arquivo excel) para que o bot armazene os dados coletados. Em segundo lugar, o bot deve ser programado e laçado através de consultas de busca e resultados de carregamento. Finalmente, o bot da RPA pode analisar os dados relevantes, extraí-los e armazená-los de forma rápida e precisa.
Os bots RPA para Web executam todas as aplicações de raspagem da web em tempo real com uma taxa de erro próxima a zero em comparação com os processos manuais.
Como realizar a raspagem com a ElectroNeek
Vamos usar a ferramenta de raspagem da web da ElectroNeek como um exemplo para ilustrar como funciona a raspagem automática da web. Vamos criar um bot que raspa os dados da loja on-line da Amazon. Você também pode baixar este bot de amostra da Biblioteca de Bots da ElectroNeek: amazon-search-result.zip.
Por exemplo, queremos abrir a Amazon, encontrar livros históricos e extrair todos os links e títulos do resultado da busca. O processo de raspagem da web seguirá os passos abaixo.
Passo 1: Crie a estrutura de dados
Não precisamos emular a abertura da Amazon e a navegação para a categoria. Substituiremos todas estas ações por apenas um link que já contém o resultado da busca. Abra o navegador Google Chrome manualmente e copie e cole o link: https://www.amazon.com/b/ref=gbpp_itr_m-3_01bf_History?node=9&ie=UTF8.
Abra o ElectroNeek's Studio Pro e clique em Arquivo → Criar fluxograma de relações entre elementos.
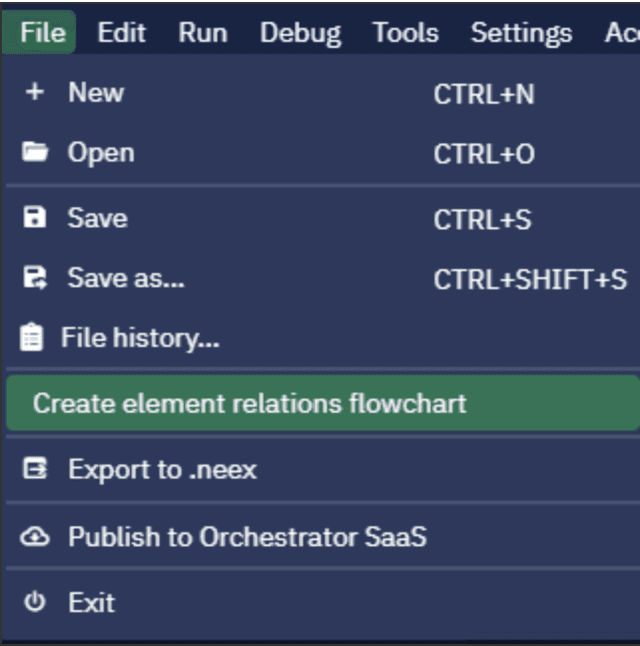
Uma tela separada se abre com um bloco Start (começar) e uma lista de funções no painel esquerdo (tem apenas uma parte agora: elemento de dados). Vamos salvar o arquivo e chamá-lo de amazon_search_result.rel.
Em seguida, construa a estrutura de dados arrastando e soltando a função Data Element (Elemento de dados) para a tela e conectando-a com o bloco Start.
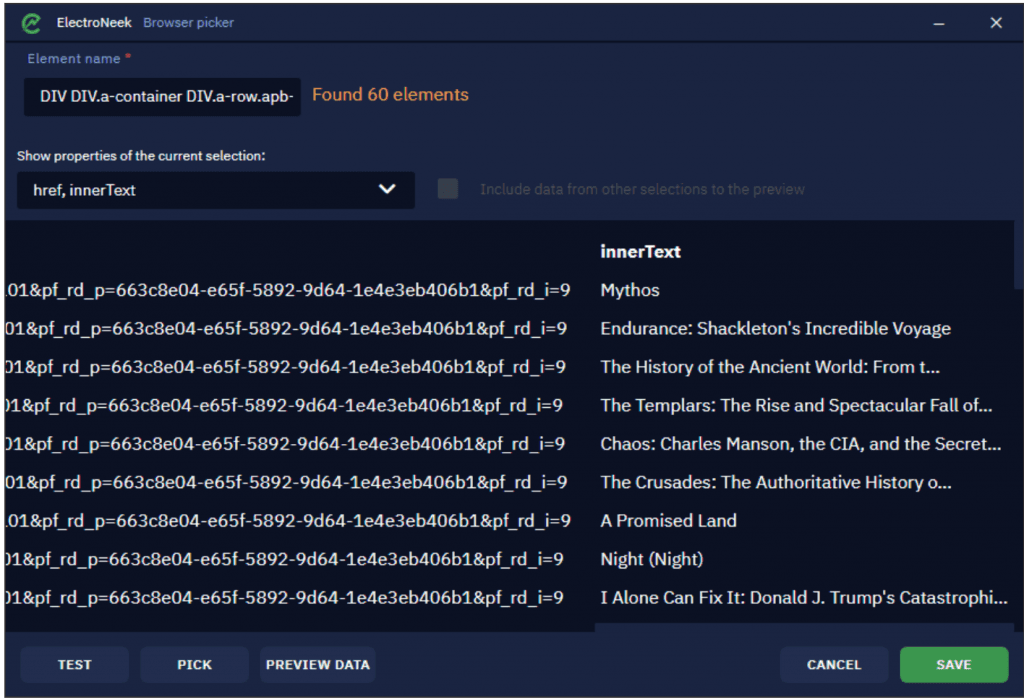
Uma vez feito isso, selecione todos os elementos necessários (títulos de livros, no nosso caso) dos quais queremos extrair dados. Clique em Pick (Escolher) novo elemento para lançar o modo de seleção. Ao clicar em Preview Data , você pode visualizar os links extraídos.
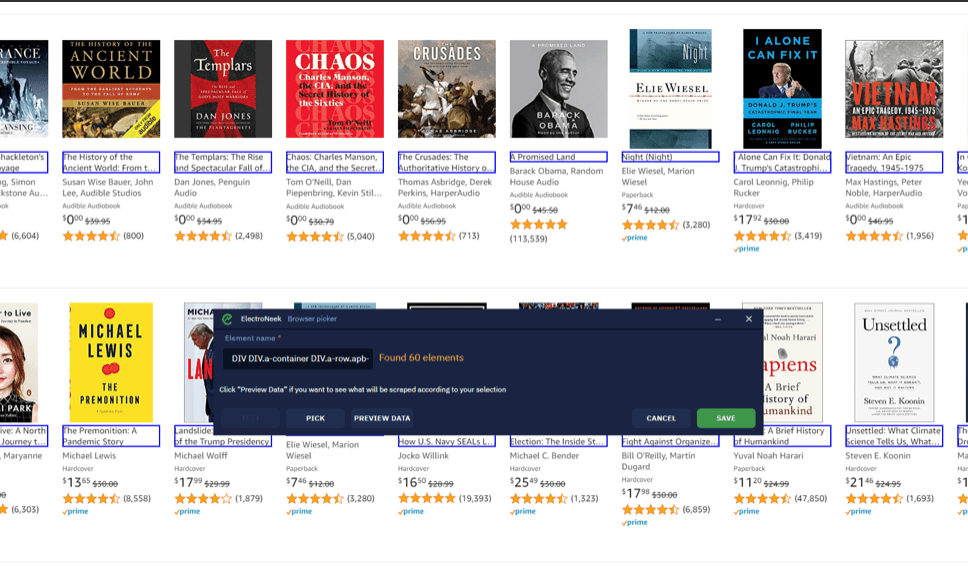
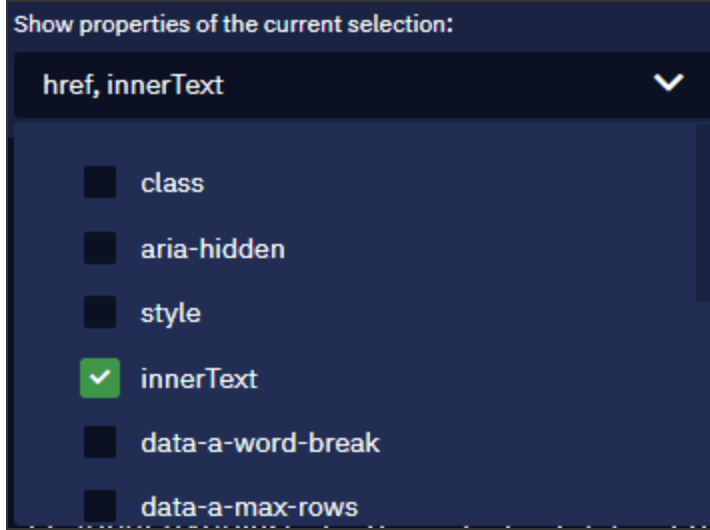
Na lista suspensa de links extraídos, você pode visualizar os atributos a partir dos quais lemos os dados. Como os títulos selecionados são essencialmente links, o atributo de saída padrão é .
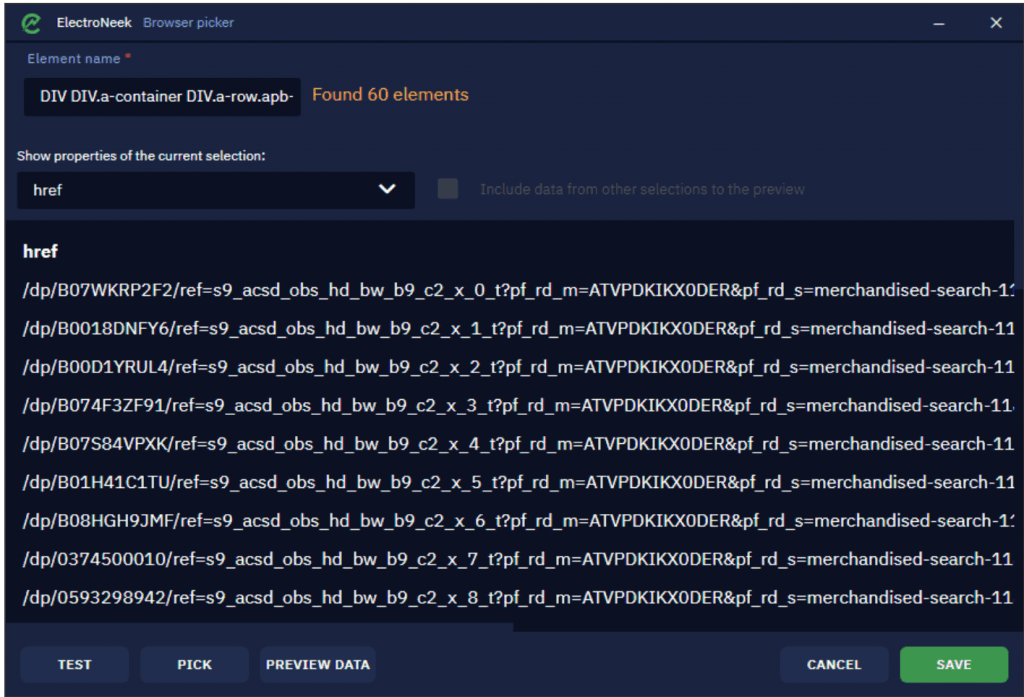
Você também pode adicionar mais atributos para ler os dados de. Clique na lista suspensa e selecione um novo atributo: . Este atributo é usado para extrair os títulos (o próprio texto).
Depois de adicionar o atributo, haverá outra coluna para visualizar o intervalo de dados, então você pode precisar rolar para a direita. Você precisa considerar o intervalo de dados para entender melhor como testar sua seleção.
Siga o processo exato para criar tantos elementos de dados quantos forem necessários.
Finalmente, antes de criar um arquivo ".neek" (Um arquivo ".neek" é um arquivo no ElectroNeek Studio; ele pode ser executado apenas no Studio pelo bot runner), você precisa testar sua estrutura de dados. Clique em Start e cole o link que postamos acima nele. O botão Test scraping (Raspagem de teste) será ativado.

Quando clicarmos em Test scraping, o bot abrirá uma nova aba e raspará os dados a partir daí. O resultado é salvo na variável na aba Variables (variáveis). Salve todas as mudanças no arquivo ".rel".
Passo 2: Configuração do bot
Arraste e solte a atividade Raspar dados estruturados a partir da seção Web Automation → Browser.
Clique no botão Pick e selecione o arquivo ".rel" que salvamos na seção anterior.
Em seguida, clique na atividade Salvar tabela após a atividade Raspar dados estruturados . Ela já está configurada de forma que o arquivo Excel resultante será colocado na mesma pasta onde o bot está localizado. Mas você pode modificá-lo, se necessário. Por exemplo, você pode salvar o resultado em uma tabela do Google Sheets. Nós o deixamos como está.

Passo 3: Execute o bot de raspagem
O último passo é executar o bot que raspará os dados e os salvará em uma tabela. Navegue até a pasta com o bot, abra a tabela, e verifique o resultado.
Por que escolher a ferramenta de raspagem da ElectroNeek
Com a ferramenta de raspagem web da ElectroNeek, você não precisa ser um engenheiro para coletar e processar automaticamente os dados que você precisa a partir da web. Não há necessidade de escrever scripts complexos - tudo que você precisa fazer é mostrar ao sistema exatamente quais dados você deseja, escolhendo vários elementos desejados (como títulos de livros históricos em nosso exemplo acima), e a ferramenta fará o resto. Normalmente, você pode esperar que a ferramenta extraia dados de um site individual em menos de um segundo.
Se estiver interessado em saber mais sobre nós e nossos bots de raspagem da web, contate nossa equipe de suporte para agendar uma demonstração e descubra como você pode aproveitar a automação de raspagem da web em seu negócio.