
UPDATED: January 2024
An AI web scraper is a tool that allows users to extract data from different websites. The web scraper takes the collected information and exports the data into a spreadsheet for deeper analysis. Web data scraping is entirely legal in the US and a helpful tool for any business.
People often spend hours manually surfing the net and collecting necessary information, which is not the most exciting task, leading to errors because of the “human factor”: tiredness or boredom.
By implementing web scraping automation, companies can extract data more efficiently and redistribute employees to more ROI-driven and crucial business tasks.
Web scraping with Robotic Process Automation (RPA) utilizes bots to automate the process of web data extraction from selected websites and store it for use. RPA delivers faster results by eliminating the need for manual data entry and reducing human errors.
How web scraping is used
There are numerous ways to use web scrapers in business processes across almost every department. From web scraping for sales and marketing teams to accounting and finance teams, we’ve put together a list of the most common AI web scraper use cases. RPA web scraping examples include:
- Extracting product details for competitor analysis.
- Gathering product information for conducting comparative shopping on platforms like Amazon, eBay, and similar websites.
- Pulling stock prices for a more data-informed investment decision.
- Monitoring brands and companies to extract valuable information.
- Utilizing an RPA AI data scraper tool for website data before a site migration.
- Using data extraction tools to gather financial information for thorough market research.
- AI-powered web scraper bots can efficiently gather information from various websites, providing valuable assistance with invoicing processes. Read this Use Case.
Once data is pulled, it gets stored in databases or transferred to another system or application. Automation not only allows to acquire data quickly but can pull actionable information and automatically store it where required, whether in a database or another system.
The opportunities to successfully implement a website scraper in your daily work are almost endless. Web scraping tools help you and your team dig deeper into particular topics to gain insightful information for strategic planning and short-term assignments.
AI Web scraping process and solutions
Web scraping data from numerous sources involves a simple algorithm tailored to each company’s goals and business requirements. The web scraping steps involve:
- Identifying relevant URLs.
- Locating necessary data for extraction.
- Writing and running the code.
- Storing data in the required format.
Many data extraction tools exist, ranging from manual copy-paste operations, and email scraper, to browser extensions and robotic process automation (RPA). RPA is the most widely adopted AI web scraper for extracting copious amounts of web data among these options.
Comparison of web scraping solutions
| Parameter | Manual Copy & Paste | Browser Extension | RPA |
| Scraping Capacity | Can scrape any quantity that is humanly possible. | Browser extensions such as ChromeScraper can scrape only one page at a time. | RPA tools such as ElectroNeek’s web scraping bot can scrape any quantity of data. |
| Cost | Inexpensive in comparison to the other two options. | Easy to install and highly customizable in comparison to the other two options. It also allows you to deal with complex UI elements easily. | Involves more expenditure than the other two options. However, with ElectroNeek’s subscription model, the initial cost is reduced drastically. |
| Time | The higher the quantity of the data to scrape, the longer the process. | It is faster than the manual process but longer than automation as it can scrape only one page at a time. | Much faster than manual and browser extension solutions. It can scrape a large quantity of data in just a few minutes. |
| Efficiency | Prone to more human errors than the other two options | A slight chance for errors as it involves more manual intervention than compared to RPA solutions. | Error-free as it involves almost no manual intervention. |
| Flexibility | Easy to do but is limited to human capacity as everything is manual. | Less flexible than RPA in terms of customization and dealing with UI elements like the ”Load more” button. | Easy to install and highly customizable in comparison to the other two options.It also allows you to deal with complex UI elements easily. |
Benefits of using RPA for web scraping
Leveraging an automated data scraping tool for websites provides the following benefits:
- The data collected by an RPA bot is more accurate in comparison to manual data entry.
- Automation makes the web scraping process faster. Tasks that take weeks to complete by hand get done within hours.
- Automation solutions are easy to implement and integrate within a company’s IT ecosystem.
- Low maintenance is needed as automated web scrapers require almost no upkeep in the long run.
RPA bots integrated with other technologies and tools such as machine learning makes the bot an even more powerful tool. For instance, machine learning combined with bots can locate companies' websites from their logos.
Challenges of using RPA for AI web scraping
An RPA site scraper depends heavily on GUI elements to locate relevant data, making it challenging to automate when web pages don't display content consistently. Some of the main web scraping limitations include:
- User Interface (UI) features: Some UI features such as infinite scrolling, popup messages, and changing dynamic web content make it difficult for scrapers to handle data extraction. The solution would be additional bot programming for specific complex features.
- ''Load more" button: Many pages load data in small parts using the ''Load more'' button. In such cases, the bot will stop at the end of a visible part end and miss further information without exploring more data. Creating an if-loop within the program of a bot to click the “load more” button until no more buttons remain on a site.
- Pop-up advertisements: These advertisements often hide GUI elements from the RPA Bots view and impair data extraction. An effective solution would be to add the ADBlocker extension to your browser.
- Protected systems: Some web pages utilize advanced security technology to prevent their site from automated scraping, which becomes another roadblock. There are two potential solutions: either partnering with a company that provides web data as a service or integrating RPA with proxy servers to develop bots indistinguishable from humans.
Automating web scraping with RPA
Automated web scraping involves RPA bots performing repetitive tasks. The bot mimics human actions in the graphical user interface (GUI) processes. The workflow is similar to the one described in the previous section; the only difference is that an RPA bot performs all the actions: from finding URLs to extracting and saving relevant data.
Unlike in the DIY workflow, with RPA, you don't have to write code every time you collect new data from new sources. The RPA platforms usually provide built-in tools for web scraping, which saves time and is much easier to use.
Let’s say you want to automate the procedure of collecting news on various topics. The first step is creating a simple file (such as an Excel file) for the bot to store collected data. Secondly, the bot must be programmed and looped through search queries and load results. Lastly, the RPA bot can parse through relevant data, and extract and store it quickly and accurately.
Web RPA bots perform all the web scraping applications in real time with a close to zero error rate compared to manual processes.
How to perform scraping with ElectroNeek
Let's use the ElectroNeek web scraper tool as an example to illustrate how automated web scraping works. We’ll create a bot that scrapes the data from the Amazon online store.
For example, we want to open Amazon, find historical books, and extract all links and titles of the search results. The web scraping process will follow the steps below.
Step 1: Create the data structure
We do not need to emulate opening Amazon and navigating to the category. We will replace all these actions with just one link that already contains the search result. Open the Google Chrome browser manually and copy and paste the link: https://www.amazon.com/b/ref=gbpp_itr_m-3_01bf_History?node=9&ie=UTF8.
Open ElectroNeek's Studio Pro and click File → Create element relations flowchart.
A separate canvas opens with a Start block on it and a list of functions on the left panel (it has only one part right now: Data element). Let's save the file and call it amazon_search_result.rel.
Next, build the data structure
By dragging and dropping the Data element function to the canvas and connecting it with the Start block.
Once you do this, select all needed elements (book titles in our case) from which we want to extract data. Click Pick New Element to launch the selection mode. By clicking Preview Data, you can view the extracted links.
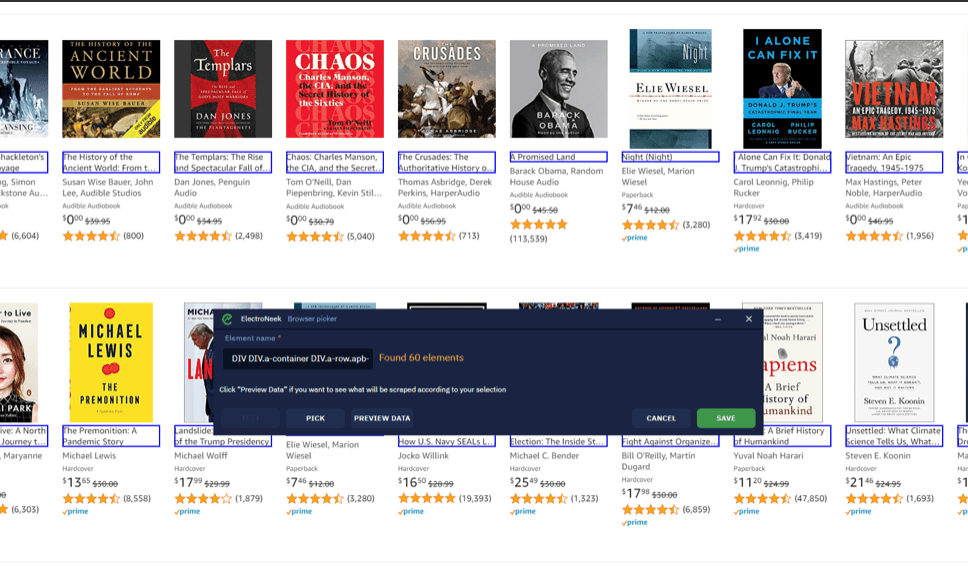
In the drop-down list of extracted links, you can view the attributes from which we read the data. As the selected titles are essentially links, the default output attribute is <href>.
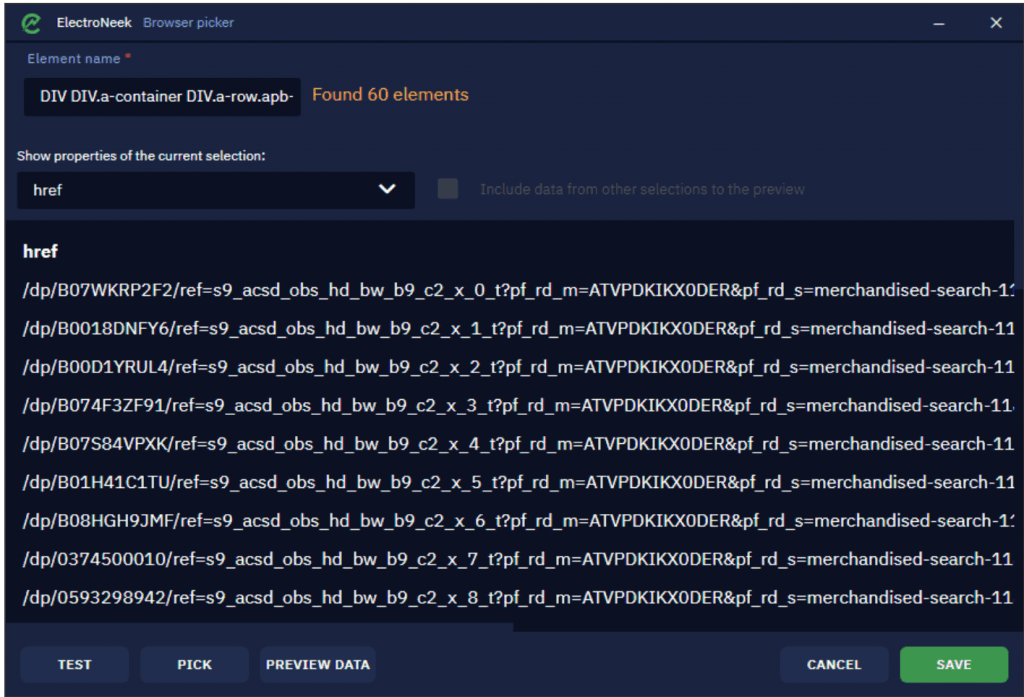
You can also add more attributes to read data from. Click on the drop-down list and select a new attribute: <innerText>. This attribute is used to extract the titles (the text itself).
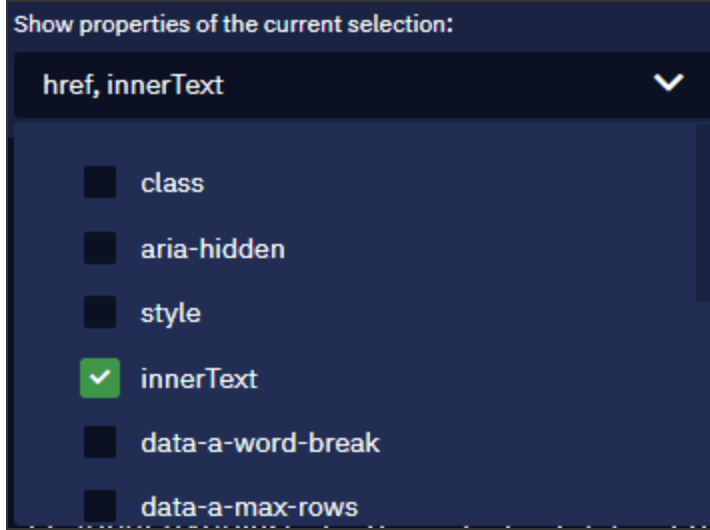
After you've added the attribute, there will be another column to view the range of data so you might need to scroll to the right. You need to consider the range of data to best understand how to test your selection.
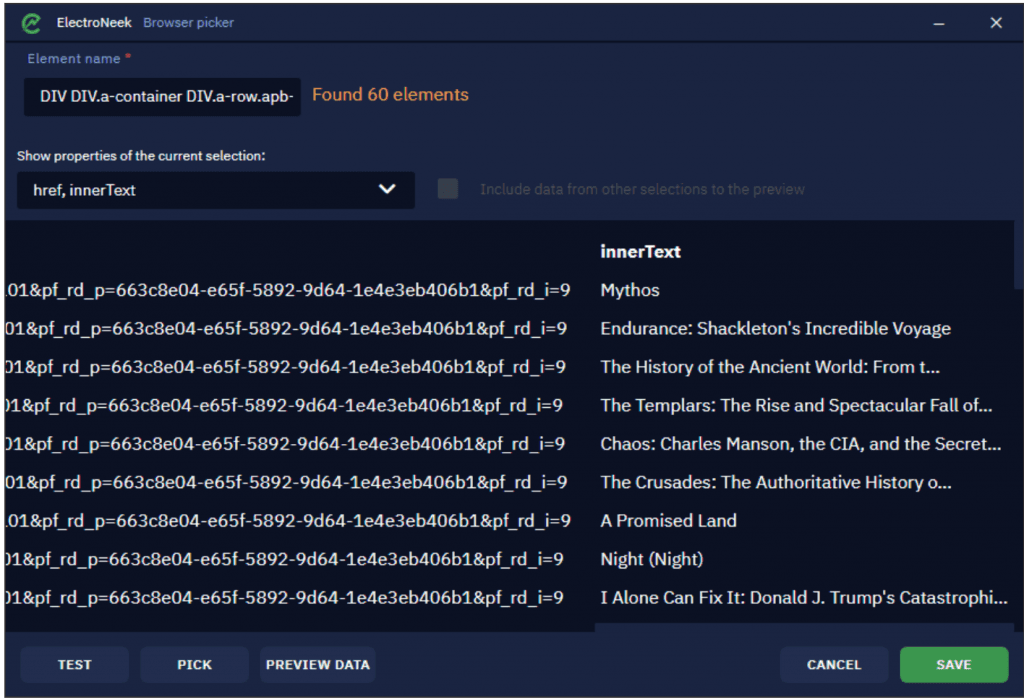
Follow the exact process to create as many data elements as needed.
Lastly, before creating a “.neek” file ( A “.neek” file is a file in ElectroNeek’s Studio; it can be run only in Studio by the bot runner), you need to test your data structure. Click Start and paste the link we posted above to it. The Test scraping button will activate.

Once we click Test Scraping, the bot will open a new tab and scrape data from there. The result gets saved to the <data_preview> variable on the Variables tab. Save all changes to the “.rel” file.
Step 2: Bot set-up
Drag and drop the Scrape structured data activity from the Web Automation → Browser section.
Click the Pick button and select the “.rel” file we saved in the earlier section.
Next, click on the Save Table activity following the Scrape structured data activity. It is already set up in a way that the resulting Excel file will be placed in the same folder where the bot is located. But you may modify it if needed. For example, you may save the result to a Google Sheets table. We leave it as it is.

Step 3: Launch the scraper bot
The last step is to launch the bot that will scrape the data and save it to a table. Navigate to the folder with the bot, open the table, and check the result.
Why choose Electroneek’s web scraping tool
With ElectroNeek’s web scraping tool, you don’t have to be an engineer to automatically collect and process the data you need from the web. There’s no need for complex script writing — all you need to do is to show the system exactly what data you want by picking several desired elements (such as historical book titles in our example above), and the tool will do the rest. Usually, you can expect the tool to extract data from an individual website in less than a second.
Learn more about ElectroNeek AI web scraping bots, contact our team to book a demo or test-drive one of our new online plans.